Building Dispo

This week marks one year since we started building Dispo. This is my reflection on what I’ve made and learned.
Back in the summer of 2020, I was at Twitter working as an ML Engineer speeding up model inference. It was a phenomenal start to my career, but I was looking for something where I could grow as more than an engineer, learn rapidly and help influence the culture of the eng team and the entire company.
When I joined as Dispo’s first hire, it was still “David’s Disposable” — an offline-only camera app that captured pictures with a disposable camera look. You couldn’t see your pics until 9 am the next day. You could order prints in-app for some time, but most people just saved them to their camera roll.
The first version was built in one go by a contract team, then left out to dry indefinitely. For an orphaned app with one function, the numbers weren’t bad. David Dobrik, being one of the biggest influencers of the past few years, had created the app with his best friend Natalie, and his fanbase alone meant anything he touched would turn to gold — as long as the proper infrastructure was in place to handle it.
Usually, when Hollywood meets Tech, there’s an imbalance in the collaboration — a celebrity is just a figurehead who approves the final product, or the flip side is a strong product that overshadows the celebrity. This time it felt like we had the chance to hit it strong from both sides in a way that hadn’t been done before. Real technologists, real influencers. As someone looking for what’s next after working at a big tech company, this was incredibly enticing.
The stars aligned, and a dream trio formed. I joined to build out the backend and early infrastructure. Shortly after, Bhoka came in to lead design, followed by Malone to build the iOS app.

Laying the Foundation
As I was getting ready to start building the Dispo backend. I kept two things in mind:
- David’s audience would bring in a large number of users early
- We wanted to have the app in TestFlight by Christmas 2020 (3 months)
I started with a Django monolith for the application. Wanted to keep things as simple as possible. The old app had no backend, so I could start fresh. Django ended up being an excellent choice for Dispo. I had lots of experience with it. Finding Python devs wouldn’t be hard when we needed to hire more engineers. There are also many libraries to do almost anything I would need. This came in handy after we launched. A user was spamming our service and we got rate limits set up within 30 minutes because there was a library already made.
On infrastructure, I decided to go with AWS. I had a decent understanding of what was needed to scale something on most cloud providers. You get a load balancer, some read replicas, maybe caching, and out comes a performant application. There were even blog posts that broke things down to the specific AWS services. Getting $100k in credits kinda restricts your choices too.
With that, I started setting up our infra in Pulumi, an infrastructure as code tool that let me stand up our infra into the AWS console. My friends Chris and Richard recommended Pulumi over Terraform. Given that Pulumi can use any Terraform provider, my decision came down to using Typescript over HCL (Hashicorp Configuration Language). They also gave me a bunch of snippets to get started with.
const cluster = new awsx.ecs.Cluster("custom", {
tags: {
"Name": "dispo-ecs-cluster",
},
});
const service = new awsx.ecs.FargateService(`${env}-${serviceName}-web`, {
cluster,
desiredCount: 1,
securityGroups: [sg],
subnets: vpcPrivateSubnetIds,
taskDefinitionArgs: {
containers: {
[serviceName]: {
image: dockerImage,
memory: 2048,
cpu: 1024,
portMappings: [targetGroup],
...
},
},
},
});Developing the Moment
 First thing to go through my backend 📸: Malone Hedges
First thing to go through my backend 📸: Malone Hedges
After standing up the application and infrastructure, I spent the next few months building out features. We had a great app that we now needed to be polished for release. It was January 2021, a couple weeks after our initial target. Looking back on it, we didn’t even have a lock on the features we wanted to be completed. Christmas 2020 just sounded nice. David had other projects going on, and his fans were rushing to try out the product. Which was good for me. I wanted to see how things performed with actual users.
Then came the tweet that led to the most exciting and stressful 30 days for me. I anticipated a few hundred users joining, but it spread like wildfire, and the TestFlight filled up (10k) in under 48 hours.
🚀 hey friends, if you’re interested in the @DispoHQ beta, I have a limited number of TestFlight invites
— Bhoka 🪶 (@boop) February 12, 2021
(iPhone only, comment below and I will DM you for phone number)
So what went wrong? Well… a lot
if you see one of my services not working, it’s jus a lil shy and everything is still working 😊😊😊
— regynald (@negroprogrammer) February 12, 2021
I didn’t mask any unintentional errors that were surfaced to users, so people saw weird API responses for hours after we went live. I was making changes and going straight to prod. Times were rough back then. Hotfix after hotfix.
dispo is objectifying me pic.twitter.com/BtcwAe8Hzx
— dilick.eth (🍞) (@imdilick) February 13, 2021
As users started coming in, I quickly noticed I had written some nasty queries. The quick fixes were seeing what indexes were needed and adding them. Our Postgres instance was running on a T3 (burstable general compute) class machine, and there wasn’t a pressing need to upgrade to something with sustained performance yet (M5, M6g) yet. The constraint helped a bit. I couldn’t just throw money at the problem. Our biggest issue on (TestFlight) launch day was with querying “all rolls.” This would fetch every roll you were a member of (public and private), rolls you were following (public), and rolls people you were following were members of (public). It’s performing a ton of joins, and this scales poorly with a read-intensive system.
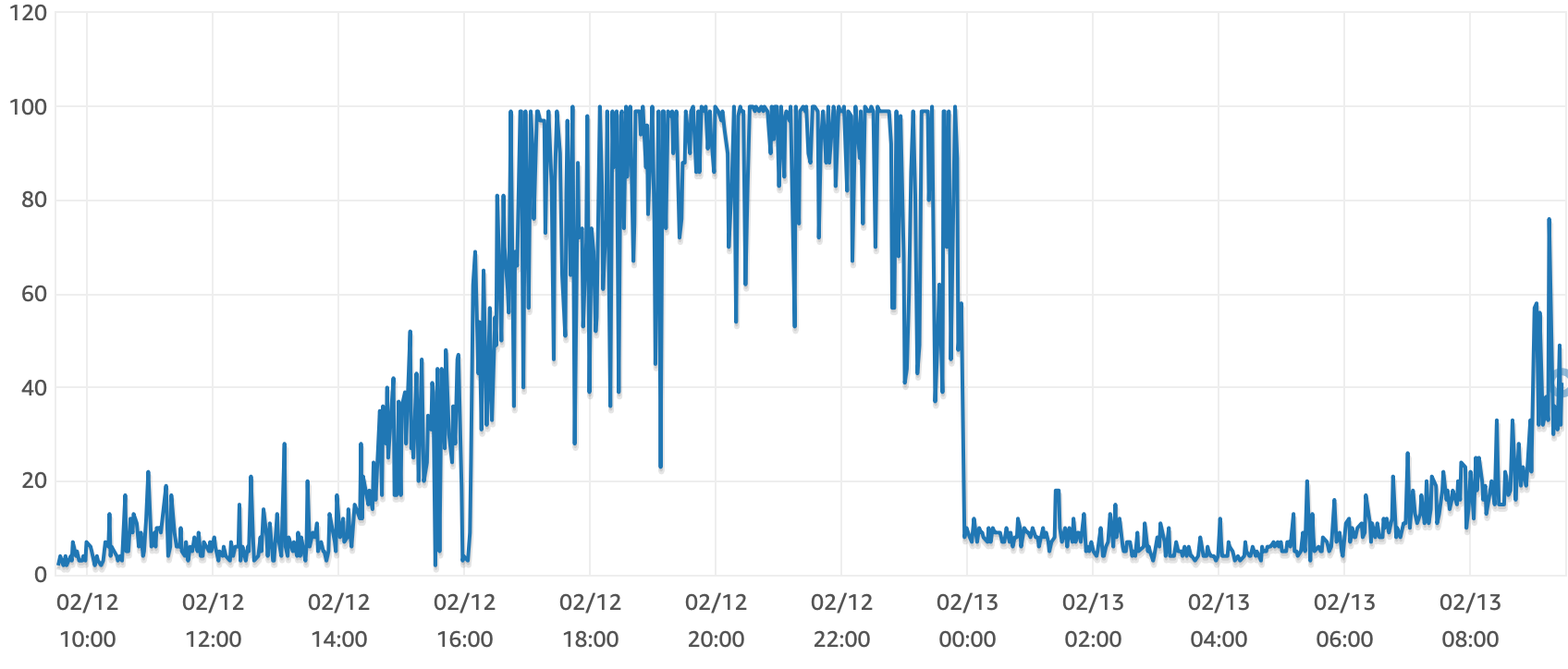
We had no read replicas set up yet, and our DB CPU% was chilling at 100%, only coming down when the service went out because health checks were failing. Fixed most of this by going into RDS Performance Insights and simplifying all queries causing high load.
Having user and roll search powered by Postgres trigram indexes didn’t help the database situation either. This was quickly fixed by moving to Algolia. They had a very handy Django library. Made setting up a basic index for users pretty easy:
class UserIndex(AlgoliaIndex):
index_name = "dispo_users"
fields = ("handle", "display_name", "avatar", "bio", "verified", "relevance")
update_fields = ("handle", "display_name", "avatar", "bio", "verified", "relevance")
should_index = "is_full_user"
settings = {
"separatorsToIndex": [".", "_", "-"],
"searchableAttributes": ["handle", "display_name"],
"customRanking": ["desc(relevance)"],
"hitsPerPage": 30,
}The last major issue during TestFlight was the weirdest. We were using SMS verification as an onboarding step, but for some reason, AT&T users couldn’t receive texts from any of our Twilio numbers. We had ~100 phone numbers in a messaging service sender pool. Through googling, it looked like AT&T (and possibly other carriers) were blocking our long code (10 digit) numbers from sending A2P (Application to Person) messages.
Tyler Faux gave a brilliant suggestion to randomize the copy we sent to users so we wouldn’t be considered spam by carriers. Helped a little bit, but eventually, we decided to just move to Twilio Verify and buy our way out of the problem. We didn’t need to reinvent the wheel here. Our app was for taking and sharing images, not sending SMS. Managed services to help you sleep became my mantra.
Launch and Learn
We spent a few weeks in TestFlight to get everything prepared. It felt as if all eyes were on us after our beta. Malone and I had gotten it done. 6 months of grinding to this moment. We finally launched!
Dispo 2.0 hit 1 Million users within days of going live. Because of the prep work we did during TestFlight, we had a lot less downtime. Things generally went pretty well, considering we only had 2 engineers and one of the biggest influencers shepherding people our way. Infra work at this point was a continuation of finding what queries weren’t performing at this new scale and simplifying or adding indexes as needed.
Here are the key takeaways:
- Query analysis and Database indices can be all the difference - early on, we tried adding several read replicas to help with the load, but that ended up being a bandaid solution that didn’t help stabilize our metrics.
- Don’t underestimate the work before it’s begun — with this being my first startup, it was naive to self-impose a timeline where nothing went wrong. Plan for there to be Plan B when things go wrong.
- Hire early - Dispo 2.0 was made almost entirely by Malone and me. Had we gotten another engineer earlier, it could have made all the difference with handling outages, getting users off the waitlist, or someone to share the on-call load with. The bus problem is very real.
- Put yourself out there - leaning on my friends, previous coworkers, and Twitter at large really helped me bring this together.
who's nice with cassandra? TAP IN 📲
— regynald (@negroprogrammer) February 13, 2021
also who nice with feeds? hit my line!! - Scaling is continuous even when growth isn’t - in building Dispo, I’ve come to see scaling as solving a set of problems that unlocks new problems for you to solve.
An incredibly happy ending to a long grind. But the real lessons were the friends I made along the way 🥺. If anyone is currently building early products, I would love to chat and help out if possible. Hit my line on Twitter!
Thanks to: Jess, Mila, Freia, Andrés, Jacky, Gonzalo, Jake, Pim, the Dispo team, and so many others!